数数数据模型与报表实现探索
数据模型
数据在数数中的组织方式
特点
数数的所有事件表数据都是存在一张大表中 ta.v_event_{appid} ,它有下面这些特点:
事件名是这大表中的一个字段名(event_name)。
它的字段是所有事件字段的合集。
都有#distinct_id和#account_id,然后由这两者去查找填充user_id (💡)。
举例
A事件日志有属性a1,a2,a3,a4,a5
B事件日志有属性b1,b2,b3,b4,a1
在ta.v_event_{appid}大表中存储的数据也即下面的样子。
| event_name | a1 | a2 | a3 | a4 | a5 | b1 | b2 | b3 | b4 | … |
|---|---|---|---|---|---|---|---|---|---|---|
| A | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ | … |
| B | ✅ | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ | ✅ | ✅ | … |
| … | … | … | … | … | … | … | … | … | … | … |
优势
- 查询性能优化 避免了复杂的JOIN操作,所有事件数据在一张表中,查询时直接扫描即可对于漏斗分析、留存分析等需要跨事件查询的场景,性能提升显著减少了多表关联的计算开销。
- 灵活的属性扩展 新增事件或属性时,只需在大表中添加新列,不需要创建新表支持动态schema。
- 存储和压缩效率 列式存储对于筛选和压缩更加友好。
用户识别规则
在用户识别规则上,数数和神策略有不同。
数数用户识别规则
三种核心id
用户ID (user_id) - 系统内部唯一标识。
账号ID (account_id) - 用户登录后的标识(数数建议用角色ID,但是这是不是对账号+角色体系不太友好?)。
访客ID (distinct_id) - 用户未登录状态的标识,由SDK自动生成。
核心规则
用户ID最重要:所有数据必须关联到一个用户ID。
优先级:有账号ID时用账号ID关联,没有时用访客ID关联。
绑定机制
一个用户ID只能对应一个账号ID。
一个账号ID可以绑定多个访客ID。
一个访客ID只能绑定一个账号ID。
简单判断逻辑
新访客ID:创建新用户ID。
访客ID存在但未绑定账号:新账号ID可与其绑定。
访客ID已绑定账号:新账号ID不能与其绑定,创建新用户ID。
同时有账号ID和访客ID:以账号ID关联的用户ID为准。
报表实现探索
几乎所有的报表操作都会围绕event和user表+user_id为核心关联条件展开,无法实现的可以使用SQL。
这里需要注意的是,某个维度只有是所有事件共有的事件属性或者是用户属性才能被作为分组项或者是全局筛选项。
事件属性:也即单个埋点中的字段。
用户属性:是属于用户的特征属性,比如性别,年龄,余额等。
单事件指标
SELECT
*,
count(data_map_0) OVER () AS group_num_0,
count(1) OVER () AS group_num
FROM
(
SELECT
map_agg("$__Date_Time", amount_0) FILTER (WHERE amount_0 IS NOT NULL AND is_finite(amount_0)) AS data_map_0,
sum(amount_0) FILTER (WHERE is_finite(amount_0) AND ("$__Date_Time" <> timestamp '1981-01-01')) AS total_amount
FROM
(
SELECT
CAST(ta_date_trunc('day', "#event_time", 1) AS TIMESTAMP) AS "$__Date_Time",
CAST(coalesce(COUNT(DISTINCT "#device_id"), 0) AS DOUBLE) AS amount_0
FROM
v_event_22
WHERE
"$part_event" IN ('ta_app_start')
AND "$part_date" = '2024-09-10'
GROUP BY
"$__Date_Time"
) AS sub
) AS aggregated_data
ORDER BY
total_amount DESC;
这段SQL是去除多余嵌套后的结果,没人知道map_agg("$__Date_Time", amount_0) FILTER (WHERE amount_0 IS NOT NULL AND is_finite(amount_0)) AS data_map_0,,sum(amount_0) FILTER (WHERE is_finite(amount_0) AND ("$__Date_Time" <> timestamp '1981-01-01')) AS total_amount这种东西到底是为了做什么,所以直接根据结果去找我们期望的东西⬇️,合理了。
SELECT
CAST(ta_date_trunc('day', "#event_time", 1) AS TIMESTAMP) AS "$__Date_Time", -- 日期
CAST(coalesce(COUNT(DISTINCT "#device_id"), 0) AS DOUBLE) AS amount_0 -- 去重设备数
FROM
v_event_22
WHERE
"$part_event" IN ('ta_app_start') -- 筛选启动日志
AND "$part_date" = '2024-09-10' -- 分区过滤
GROUP BY
"$__Date_Time"
数数的查询是必须带有分区的,但是即使这样,在同一天中,所有日志放在同一个表中,使用 in 过滤某个表还是会扫描大量数据。数数作为一款商业化产品,这些底层技术细节当然是对用户不透明的,所以我们只能猜测在同个分区中可能按event_name做了某种索引或者分桶操作。
下面可以基于上述的这个简单查询得到一个基本前提:
- 查询必须带有分区条件
- 对事件(event_name)过滤是高效的(假设)
- 选取仅需要的列
多事件指标
/* SQL for Events: 1 */
/* sessionProperties: {"ignore_downstream_preferences":"true","join_distribution_type":"BROADCAST"} */
SELECT
map_agg("$__Date_Time", amount_0) FILTER (WHERE amount_0 IS NOT NULL AND is_finite(amount_0)) AS data_map_0,
sum(amount_0) FILTER (WHERE is_finite(amount_0) AND ("$__Date_Time" <> timestamp '1981-01-01')) AS total_amount,
count(map_agg("$__Date_Time", amount_0) FILTER (WHERE amount_0 IS NOT NULL AND is_finite(amount_0))) OVER () AS group_num_0,
count(1) OVER () AS group_num
FROM
(
SELECT
CAST("$part_date" AS TIMESTAMP) AS "$__Date_Time",
CAST(coalesce(COUNT(1), 0) AS double) AS amount_0
FROM
v_event_22
WHERE
"$part_event" IN ('ta_app_install') AND "$part_date" = '2025-05-22'
GROUP BY
"$part_date"
) AS subquery
ORDER BY
total_amount DESC
LIMIT 1000;
---
/* SQL for Events: 2 */
/* sessionProperties: {"ignore_downstream_preferences":"true","join_distribution_type":"BROADCAST"} */
SELECT
map_agg("$__Date_Time", amount_0) FILTER (WHERE amount_0 IS NOT NULL AND is_finite(amount_0)) AS data_map_0,
sum(amount_0) FILTER (WHERE is_finite(amount_0) AND ("$__Date_Time" <> timestamp '1981-01-01')) AS total_amount,
count(map_agg("$__Date_Time", amount_0) FILTER (WHERE amount_0 IS NOT NULL AND is_finite(amount_0))) OVER () AS group_num_0,
count(1) OVER () AS group_num
FROM
(
SELECT
CAST("$part_date" AS TIMESTAMP) AS "$__Date_Time",
CAST(coalesce(COUNT(1), 0) AS double) AS amount_0
FROM
v_event_22
WHERE
"$part_event" IN ('ta_app_start') AND "$part_date" = '2025-05-22'
GROUP BY
"$part_date"
) AS subquery
ORDER BY
total_amount DESC
LIMIT 1000;
与单事件指标一样的,事件与事件各算各的。
(吐槽)为啥不优化成下面这种形式:
select '2025-05-22' as dt
,sum(if("#event_name"='ta_app_install',1,0)) cnt_install
,sum(if("#event_name"='ta_app_start',1,0)) cnt_start
from ta.v_event_22
where "#event_name" in('ta_app_install' ,'ta_app_start')
and "$part_date"='2025-05-22' ;
留存分析
SELECT
count(1) user_num,
retention_lost_date_collect_agg(init_date_array,coalesce(return_date_array, X''),7,'day') retention_lost_data
FROM (
SELECT
virtual_user_id,
ta_date_collect(trunc_date) filter (where is_init) init_date_array, -- ta_date_collect应该是个聚合函数
ta_date_collect(trunc_date) filter (where is_return) return_date_array
FROM (
-- 初始化事件数据
SELECT
"#user_id" as virtual_user_id,
ta_date_trunc('day', "#event_time", 1) as trunc_date,
true as is_init, -- 是否初始化
false as is_return -- 是否回访
FROM v_event_22
WHERE "$part_event" = 'ta_app_install'
AND "$part_date" BETWEEN '2025-05-22' AND '2025-05-28' -- 初始化事件的筛选范围是 计算当天的-7天到 2025-05-28
AND "#user_id" IS NOT NULL
UNION ALL
-- 返回事件数据
SELECT
"#user_id" as virtual_user_id,
ta_date_trunc('day', "#event_time", 1) as trunc_date,
false as is_init, -- 是否初始化
true as is_return -- 是否回访
FROM v_event_22
WHERE "$part_event" = 'ta_app_start'
AND "$part_date" BETWEEN '2025-05-22' AND '2025-06-04' -- 回访事件的筛选范围是 计算当天的(2025-05-28)±7天
AND "#user_id" IS NOT NULL
) ta_ev
GROUP BY virtual_user_id
HAVING bool_or(is_init) -- 确保用户有初始化事件
)
ORDER BY user_num DESC
这里就比较明显了,使用group by代替join,上面这个SQL得到的留存/流失结果如下:
{
0:{
1747843200000:[3975,3956,2280,1582,1232,1133,1001,900,726],
1747929600000:[3545,3524,1910,1315,1094,939,825,620,1],
1748016000000:[3468,3445,1875,1287,1009,852,635,0,0],
1748102400000:[3430,3404,1715,1159,906,664,0,0,0],
1748188800000:[2921,2909,1451,964,662,0,0,0,0],
1748275200000:[2239,2218,1117,700,1,0,0,0,0],
1748361600000:[2665,2656,1279,1,0,0,0,0,0]},
1:{
1747843200000:[3975,3975,1695,1490,1404,1349,1316,1298,1283],
1747929600000:[3545,3545,1635,1442,1330,1279,1256,1232,1232],
1748016000000:[3468,3468,1593,1383,1306,1255,1231,1231,1231],
1748102400000:[3430,3430,1715,1550,1473,1434,1434,1434,1434],
1748188800000:[2921,2921,1470,1335,1290,1290,1290,1290,1290],
1748275200000:[2239,2239,1122,1027,1027,1027,1027,1027,1027],
1748361600000:[2665,2665,1386,1386,1386,1386,1386,1386,1386]
}}
其中0代表留存,1代表流失,数数是默认将这两个指标同时算出来的。
留存
拿1747843200000:[3975,3956,2280,1582,1232,1133,1001,900,726]这组数据为例得到的留存为:
| 日期 | 当日安装 | 当日留存 | 1日留存 | 2日留存 | 3日留存 | 4日留存 | 5日留存 | 6日留存 | 7日留存 |
|---|---|---|---|---|---|---|---|---|---|
| 2025-05-22 | 3975 | 3956 | 2280 | 1582 | 1232 | 1133 | 1001 | 900 | 726 |
流失
跟留存一样,不过数数这里的流失是连续N日未触发回访事件。
这种算法的思路是将单条用户的初始日期与回访日期放到一行记录中,然后使用滑动+累计窗口的方式计算。
这里尝试使用Hive UDF实现这个思路:
public class RetentionCalculatorUDF extends UDF {
private static final DateTimeFormatter DATE_FORMAT = DateTimeFormatter.ofPattern("yyyyMMdd");
private static final ObjectMapper objectMapper = new ObjectMapper();
public Text evaluate(Text userId, List<Text> initialDates, List<Text> visitDates, Integer window) {
String userIdStr = userId.toString();
List<LocalDate> initDates = parseTextListToDates(initialDates);
//将Text列表转换为LocalDate列表
Set<LocalDate> visitDateSet = new HashSet<>(parseTextListToDates(visitDates));
List<RetentionRecord> records = new ArrayList<>();
// 遍历每个初始日期
for (LocalDate initDate : initDates) {
RetentionRecord record = calculateRetention(userIdStr, initDate, visitDateSet, window);
records.add(record);
}
return new Text(convertToJson(records));
}
// 计算单个初始日期的留存情况
private RetentionRecord calculateRetention(String userId, LocalDate initDate, Set<LocalDate> visitDateSet, int window) {
List<Integer> retentions = new ArrayList<>();
// 计算窗口期内每天的留存
for (int day = 0; day <= window; day++) {
LocalDate targetDate = initDate.plusDays(day);
int retained = visitDateSet.contains(targetDate) ? 1 : 0;
retentions.add(retained);
}
return new RetentionRecord(userId, initDate.format(DATE_FORMAT), retentions);
}
//留存记录数据结构
public static class RetentionRecord {
private String userId;
private String initialDate;
private List<Integer> retentions;
}
}
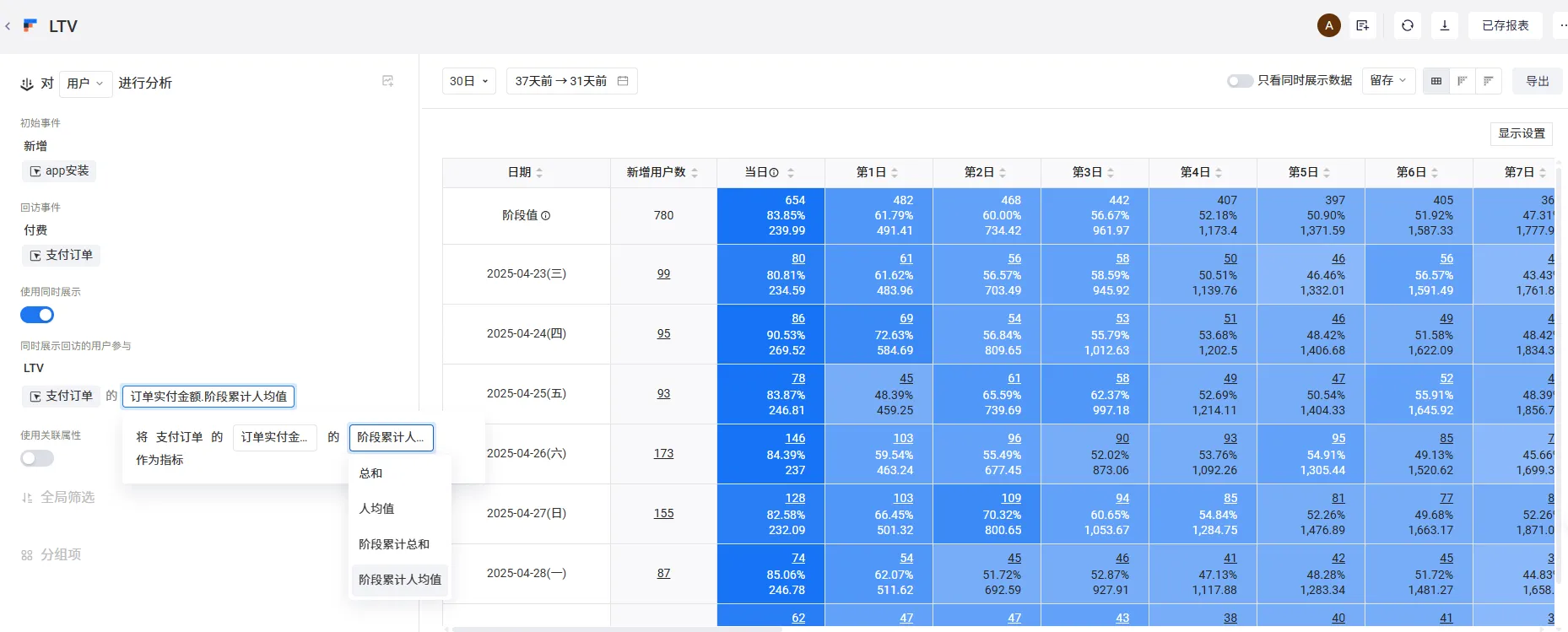
可以看到还能打开同时展示,可以看到这类型的 留存 、流失、LTV、LT、ROI 的计算方式都类似,可以连带着出来。
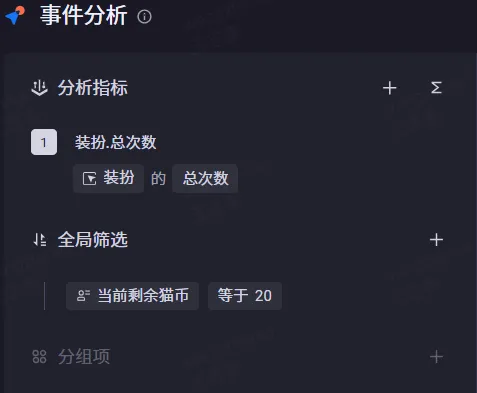
全局筛选用户属性
select *
from (
select *, count(data_map_0) over () group_num_0, count(1) over () group_num
from (
select map_agg("$__Date_Time", amount_0) filter (where amount_0 is not null and is_finite(amount_0) ) data_map_0,sum(amount_0) filter (where is_finite(amount_0) and ("$__Date_Time" <> timestamp '1981-01-01')) total_amount
from (
select *, internal_amount_0 amount_0
from (
select cast("$part_date" as TIMESTAMP) "$__Date_Time", cast(coalesce(COUNT(1), 0) as double) internal_amount_0
from (
select *, ta_date_trunc('day', "@vpc_tz_#event_time", 1) "$__Date_Time"
from (
SELECT *
from (
select *, "#event_time" "@vpc_tz_#event_time"
from (
select "#event_name", "#user_id", "#event_time", "$part_date", "$part_event"
from v_event_22
)
)
)
) ta_ev
inner join (
select *
from (
select "#update_time", "#event_date", "#user_id", "current_cat_coin"
from v_user_22
)
where "#event_date" > 20250516
) ta_u on ta_ev."#user_id" = ta_u."#user_id"
where ((("$part_event" IN ('dress_up')))) and
(("$part_date" between '2025-05-23' and '2025-05-29') and (ta_u."current_cat_coin" IN (20)))
group by "$part_date"
)
)
)
)
ORDER BY total_amount DESC;
可以看到这种分开的用户表和事件表还是会走join的。后面测试了多事件全局用户属性筛选,以及用户属性分组,都是会存在join的。
结论
- 不涉及到用户表的报表,数数会尽量使用group by来替代join(目前没发现不是的),并且它底层的存储设计使这种方式更高效。
- 涉及用户表+事件表的报表,始终会存在user表和event表的join(通过user_id),这里需要知道user表和event表始终能关联。
- 在多事件报表中,数数不会一次性的使用in(‘a’,‘b’,‘c’)这种方式来筛选多个事件,而是单独筛选然后使用union all。
- 由于设计上的取舍,数数是无法支持自由的关联的,部分报表还是需要借助SQL完成。